Optimizing a Classifier
This tutorial walks through optimizing a classifier based on user a feedback. Classifiers are great to optimize because its generally pretty simple to collect the desired output, which makes it easy to create few shot examples based on user feedback. That is exactly what we will do in this example.
The objective
In this example, we will build a bot that classify GitHub issues based on their title. It will take in a title and classify it into one of many different classes. Then, we will start to collect user feedback and use that to shape how this classifier performs.
Getting started
To get started, we will first set it up so that we send all traces to a specific project. We can do this by setting an environment variable:
import os
os.environ["LANGCHAIN_PROJECT"] = "classifier"
We can then create our initial application. This will be a really simple function that just takes in a GitHub issue title and tries to label it.
import openai
from langsmith import traceable, Client
import uuid
client = openai.Client()
available_topics = [
"bug",
"improvement",
"new_feature",
"documentation",
"integration",
]
@traceable(
run_type="chain",
name="Classifier",
)
def topic_classifier(
topic: str
):
return client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": f"Classify the type of issue as one of {','.join(available_topics)}\n\nIssue: {topic}"}],
).choices[0].message.content
We can then start to interact with it. When interacting with it, we will generate the LangSmith run id ahead of time and pass that into this function. We do this so we can attach feedback later on.
Here's how we can invoke the application:
run_id = uuid.uuid4()
topic_classifier(
"fix bug in LCEL",
langsmith_extra={"run_id": run_id}
)
Here's how we can attach feedback after. We can collect feedback in two forms.
First, we can collect "positive" feedback - this is for examples that the model got right.
ls_client = Client()
run_id = uuid.uuid4()
topic_classifier(
"fix bug in LCEL",
langsmith_extra={"run_id": run_id}
)
ls_client.create_feedback(
run_id,
key="user-score",
score=1.0,
)
Next, we can focus on collecting feedback that corresponds to a "correction" to the generation. In this example the model will classify it as a bug, whereas I really want this to be classified as documentation.
ls_client = Client()
run_id = uuid.uuid4()
topic_classifier(
"fix bug in documentation",
langsmith_extra={"run_id": run_id}
)
ls_client.create_feedback(
run_id,
key="correction",
correction="documentation"
)
Set up automations
We can now set up automations to move examples with feedback of some form into a dataset. We will set up two automations, one for positive feedback and the other for negative feedback.
The first will take all runs with positive feedback and automatically add them to a dataset.
The logic behind this is that any run with positive feedback we can use as a good example in future iterations.
Let's create a dataset called classifier-github-issues to add this data to.
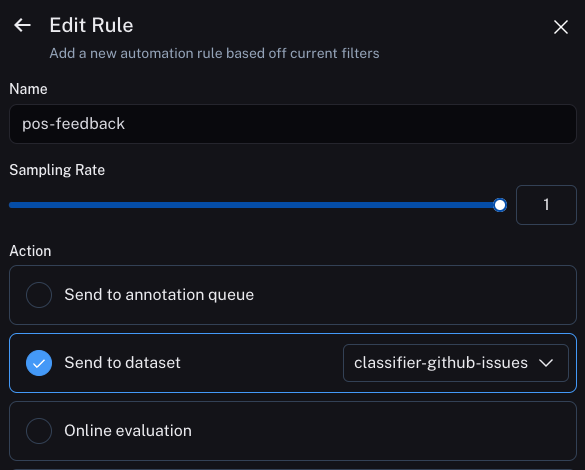
The second will take all runs with a correction and use a webhook to add them to a dataset
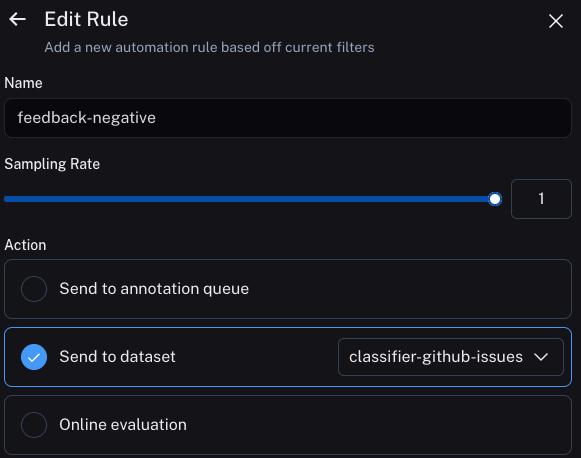
In order to do this, we need to set up a webhook. We will do this using Modal. To see in-depth instructions on this, see instructions here.
The Python file that defines our Modal service should look like:
from fastapi import Depends, HTTPException, status, Request, Query
from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials
from modal import Secret, Stub, web_endpoint, Image
from langsmith import Client
# Create a job called "auth-example" that install the `langsmith` package as a dependency
# Installing `langsmith` is just an example, you may need to install other packages
# depending on your logic.
stub = Stub("auth-example", image=Image.debian_slim().pip_install("langsmith"))
# These are the secrets we defined above
@stub.function(
secrets=[
Secret.from_name("ls-webhook"),
Secret.from_name("my-langsmith-secret")
]
)
# We want this to be a `POST` endpoint since we will post data here
@web_endpoint(method="POST")
# We set up a `secret` query parameter
async def f(request: Request, secret: str = Query(...), ):
# First, we validate the secret key we pass
import os
if secret != os.environ["LS_WEBHOOK"]:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect bearer token",
headers={"WWW-Authenticate": "Bearer"},
)
# Now we load the JSON payload for the runs that are passed to the webhook
body = await request.json()
# We get all runs
runs = body['runs']
ls_client = Client()
# We get the ids of the runs we are passed
ids = [r['id'] for r in runs]
# We fetch feedback for all those runs
feedback = list(ls_client.list_feedback(run_ids=ids))
# We then iterate over these runs and associated feedback
for r, f in zip(runs, feedback):
# We create an example in the dataset
# This example has the same inputs as our application
# But the outputs are now the "correction" that we left as feedback
ls_client.create_example(
inputs=r['inputs'],
outputs={'output': f.correction},
dataset_name="classifier-github-issues"
)
# Function body
return "success!"
Updating the application
We can now update our code to pull down the dataset we are sending runs to.